
В области искусственного интеллекта (ИИ) сила и потенциал больших языковых моделей (LLM) неоспоримы, особенно после новаторских релизов OpenAI, таких как ChatGPT и GPT-4. Сегодня на рынке существует множество проприетарных LLM с открытым исходным кодом, которые революционизируют отрасли и вносят кардинальные изменения в функционирование бизнеса. Несмотря на быструю трансформацию, существует множество уязвимостей и недостатков LLM, которые необходимо устранить.
Например, LLM могут использоваться для проведения кибератак, таких как скрытый фишинг, путем массовой генерации персонализированных фишинговых сообщений, похожих на человеческие. Последние исследования показывают, насколько легко создавать уникальные фишинговые сообщения с использованием GPT-моделей OpenAI путем создания базовых подсказок. Если их не устранить, уязвимости LLM могут поставить под угрозу применимость LLM в масштабе предприятия.
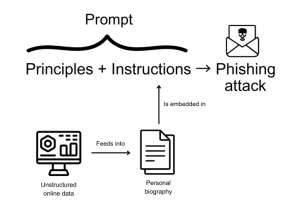
Иллюстрация фишинг-атаки с использованием spire, основанной на LLM
В этой статье мы рассмотрим основные уязвимости LLM и обсудим, как организации могли бы преодолеть эти проблемы.
Топ-10 уязвимостей LLM и способы их устранения
Поскольку мощь LLM продолжает стимулировать инновации, важно понимать уязвимости этих передовых технологий. Ниже приведены топ-10 уязвимостей, связанных с LLM, и шаги, необходимые для решения каждой проблемы.
1. Отравление обучающих данных
Производительность LLM в значительной степени зависит от качества обучающих данных. Злоумышленники могут манипулировать этими данными, внося предвзятость или дезинформацию для компрометации результатов.
Решение
Для устранения этой уязвимости необходимы тщательные процессы обработки и валидации данных. Регулярные аудиты и проверки разнообразия в данных обучения могут помочь выявить и устранить потенциальные проблемы.
2. Несанкционированное выполнение кода
Способность LLM генерировать код создает условия для несанкционированного доступа и манипулирования. Злоумышленники могут внедрять вредоносный код, подрывая безопасность модели.
Решение
Использование строгой проверки входных данных, фильтрации контента и методов изолированной обработки может противодействовать этой угрозе, обеспечивая безопасность кода.
3. Быстрое внедрение
Манипулирование LLM с помощью вводящих в заблуждение подсказок может привести к непреднамеренным выводам, способствуя распространению дезинформации. Разрабатывая подсказки, которые используют ошибки или ограничения модели, злоумышленники могут заставить ИИ генерировать неточный контент, соответствующий их повестке дня.
Решение
Установление предопределенных рекомендаций по оперативному использованию и совершенствование методов оперативного проектирования могут помочь устранить эту уязвимость LLM. Кроме того, точная настройка моделей для лучшего соответствия желаемому поведению может повысить точность реагирования.
4. Уязвимости при подделке запросов на стороне сервера (SSRF)
LLM непреднамеренно создают лазейки для атак по подделке запросов на стороне сервера (SSRF), которые позволяют субъектам угрозы манипулировать внутренними ресурсами, включая API и базы данных. Эта эксплуатация подвергает LLM несанкционированному оперативному запуску и извлечению конфиденциальных внутренних ресурсов. Такие атаки обходят меры безопасности, создавая угрозы, такие как утечки данных и несанкционированный доступ к системе.
Решение
Интеграция очистки входных данных и мониторинга сетевых взаимодействий предотвращает эксплойты на основе SSRF, повышая общую безопасность системы.
5. Чрезмерная зависимость от контента, созданного LLM
Чрезмерная зависимость от контента, сгенерированного LLM, без проверки фактов может привести к распространению неточной или сфабрикованной информации. Кроме того, LLM склонны к “галлюцинациям”, генерируя правдоподобную, но полностью вымышленную информацию. Пользователи могут ошибочно считать контент надежным из-за его согласованного внешнего вида, увеличивая риск дезинформации.
Решение
Использование человеческого контроля для проверки контента и фактов обеспечивает более высокую точность контента и поддерживает доверие.
6. Неадекватная настройка ИИ
Неадекватное согласование относится к ситуациям, когда поведение модели не соответствует человеческим ценностям или намерениям. Это может привести к тому, что LLM будут генерировать оскорбительные, неуместные или вредные результаты, потенциально нанося ущерб репутации или способствуя разногласиям.
Решение
Внедрение стратегий обучения с подкреплением для приведения поведения ИИ в соответствие с человеческими ценностями устраняет расхождения, способствуя этичному взаимодействию ИИ.
7. Неадекватная «песочница»
Изолированная среда включает ограничение возможностей LLM для предотвращения несанкционированных действий. Неадекватная изолированная среда может подвергать системы таким рискам, как выполнение вредоносного кода или несанкционированный доступ к данным, поскольку модель может выходить за намеченные границы.
Решение
Для обеспечения целостности системы решающее значение имеет формирование защиты от потенциальных взломов, которая включает в себя надежную «песочницу», изоляцию экземпляра и защиту серверной инфраструктуры.
8. Неправильная обработка ошибок
Плохо управляемые ошибки могут разглашать конфиденциальную информацию об архитектуре или поведении LLM, которую злоумышленники могут использовать для получения доступа или разработки более эффективных атак. Правильная обработка ошибок необходима для предотвращения непреднамеренного раскрытия информации, которая может помочь субъектам угрозы.
Решение
Создание комплексных механизмов обработки ошибок, которые проактивно управляют различными входными данными, может повысить общую надежность и удобство использования систем на основе LLM.
9. Кража модели
Из-за их финансовой ценности LLM могут быть привлекательными объектами для кражи. Субъекты угроз могут украсть или утечь базу кода и скопировать или использовать ее в злонамеренных целях.
Решение
Организации могут использовать шифрование, строгий контроль доступа и постоянный мониторинг для защиты от попыток кражи модели, чтобы сохранить целостность модели.
10. Недостаточный контроль доступа
Недостаточные механизмы контроля доступа подвергают LLM риску несанкционированного использования, предоставляя злоумышленникам возможности использовать модель в своих неблаговидных целях. Без надежных средств контроля доступа эти субъекты могут манипулировать контентом, созданным LLM, ставить под угрозу его надежность или даже извлекать конфиденциальные данные.
Решение
Строгий контроль доступа предотвращает несанкционированное использование, подделку или утечку данных. Строгие протоколы доступа, аутентификация пользователя и тщательный аудит предотвращают несанкционированный доступ, повышая общую безопасность.
Этические соображения при уязвимостях LLM
 Использование уязвимостей LLM влечет за собой далеко идущие последствия. Последствия этих уязвимостей — от распространения дезинформации до облегчения несанкционированного доступа — подчеркивают критическую необходимость ответственной разработки искусственного интеллекта.
Использование уязвимостей LLM влечет за собой далеко идущие последствия. Последствия этих уязвимостей — от распространения дезинформации до облегчения несанкционированного доступа — подчеркивают критическую необходимость ответственной разработки искусственного интеллекта.
Разработчики, исследователи и политики должны сотрудничать, чтобы установить надежные гарантии против потенциального вреда. Более того, устранение укоренившихся искажений в данных обучения и смягчение непреднамеренных результатов должны быть приоритетными.
Поскольку LLM все больше внедряются в нашу жизнь, этические соображения должны направлять их эволюцию, гарантируя, что технология принесет пользу обществу без ущерба для целостности.
По мере того, как мы исследуем ландшафт уязвимостей LLM, становится очевидным, что инновации сопряжены с ответственностью. Принимая ответственный ИИ и этический надзор, мы можем проложить путь к обществу, наделенному возможностями ИИ.

Author: admin
Related Posts

Еженедельный дайджест КБ, ИИ и ИТ (16–22 января 2026)

Рекомендации CISA и партнёров по безопасной интеграции ИИ в операционные технологии критической инфраструктуры
