
Генеративный ИИ использует большие наборы данных и сложные модели для имитации человеческого творчества и создания новых изображений, музыки, текста и многого другого.
Генеративный искусственный интеллект (ИИ), основанный на передовых алгоритмах и массивных наборах данных, позволяет машинам создавать оригинальный контент, революционизируя такие области, как искусство, музыка и повествование. Изучая закономерности в данных, модели генеративного ИИ раскрывают потенциал машин для создания реалистичных изображений, сочинения музыки и даже разработки целых виртуальных миров, раздвигая границы человеческого творчества.
Генеративный ИИ, объясненный
Генеративный ИИ — это передовая область, которая исследует потенциал машинного обучения для вдохновения на творческий подход, подобный человеческому, и создания оригинального материала. Генеративный ИИ — это подмножество искусственного интеллекта, занимающееся созданием алгоритмов, которые могут генерировать свежую информацию или воспроизводить шаблоны исторических данных.
Он использует такие методы, как глубокое обучение и нейронные сети, для моделирования творческих процессов человека и получения уникальных результатов. Генеративный ИИ проложил путь для приложений, начиная от генерации изображений и звука и заканчивая рассказыванием историй и разработкой игр, используя алгоритмы и обучающие модели на огромных объемах данных.
Как ChatGPT от OpenAI, так и Bard от Google демонстрируют способность генеративного ИИ понимать и создавать тексты, похожие на человеческие. У них есть множество применений, включая чат-ботов, создание контента, языковой перевод и креативное письмо. Идеи и методы, лежащие в основе этих моделей, более широко продвигают генеративный ИИ и его потенциал для улучшения взаимодействия человека и машины и художественного самовыражения.
Эволюция генеративного ИИ
Вот краткая эволюция генеративного ИИ:
- 1932: Концепция генеративного ИИ возникает в результате ранних работ над системами, основанными на правилах, и генераторами случайных чисел, закладывая основу для будущих разработок.
- 1950–е-1960-е: исследователи изучают ранние методы распознавания образов и генеративные модели, включая разработку ранних искусственных нейронных сетей.
- 1980-е годы: Область искусственного интеллекта переживает всплеск интереса, что привело к усовершенствованиям генеративных моделей, таким как разработка вероятностных графических моделей.
- 1990-е годы: Скрытые марковские модели стали широко использоваться в задачах распознавания речи и обработки естественного языка, представляя собой ранний пример генеративного моделирования.
- Начало 2000-х: набирают популярность байесовские сети и графические модели, позволяющие делать вероятностный вывод и генеративное моделирование в различных областях.
- 2012: Глубокое обучение, в частности глубокие нейронные сети, начали привлекать внимание и революционизировать область генеративного ИИ, прокладывая путь к значительным достижениям.
- 2014: Внедрение генеративных состязательных сетей (GAN) Иэном Гудфеллоу продвигает область генеративного ИИ вперед. GAN демонстрируют способность генерировать реалистичные изображения и становятся фундаментальной основой для генеративного моделирования.
- 2015-2017: Исследователи уточняют и улучшают GAN, внедряя такие вариации, как условные GAN и глубокие сверточные GAN, что позволяет осуществлять высококачественный синтез изображений.
- 2018: StyleGAN, конкретная реализация GANs, позволяет осуществлять детальный контроль над созданием изображений, включая такие факторы, как стиль, поза и освещение.
- 2019-2020: Transformers — изначально разработанные для задач обработки естественного языка — показывают многообещающие результаты в генеративном моделировании и становятся влиятельными в генерации текстов, переводе на язык и обобщении.
- Настоящее время: Генеративный ИИ продолжает быстро развиваться, при этом текущие исследования сосредоточены на улучшении возможностей моделей, решении этических проблем и изучении междоменных генеративных моделей, способных создавать мультимодальный контент.
Как работает генеративный ИИ?
С использованием алгоритмов и обучающих моделей на огромных объемах данных генеративный ИИ создает новый материал, точно отражающий шаблоны и особенности обучающих данных. В процедуре присутствуют различные важные элементы и процессы:
Сбор данных
Первым этапом является составление значительного набора данных, представляющих предмет или категорию контента, который намеревается создать генеративная модель ИИ. Например, если целью было создание реалистичных изображений животных, можно было бы собрать набор данных с помеченными фотографиями животных.
Архитектура модели
Следующий шаг — выбрать подходящую архитектуру генеративной модели. К популярным моделям относятся трансформаторы, вариационные автокодеры (VAEs) и GAN. Архитектура модели определяет, как данные будут изменены и обработаны для создания нового контента.
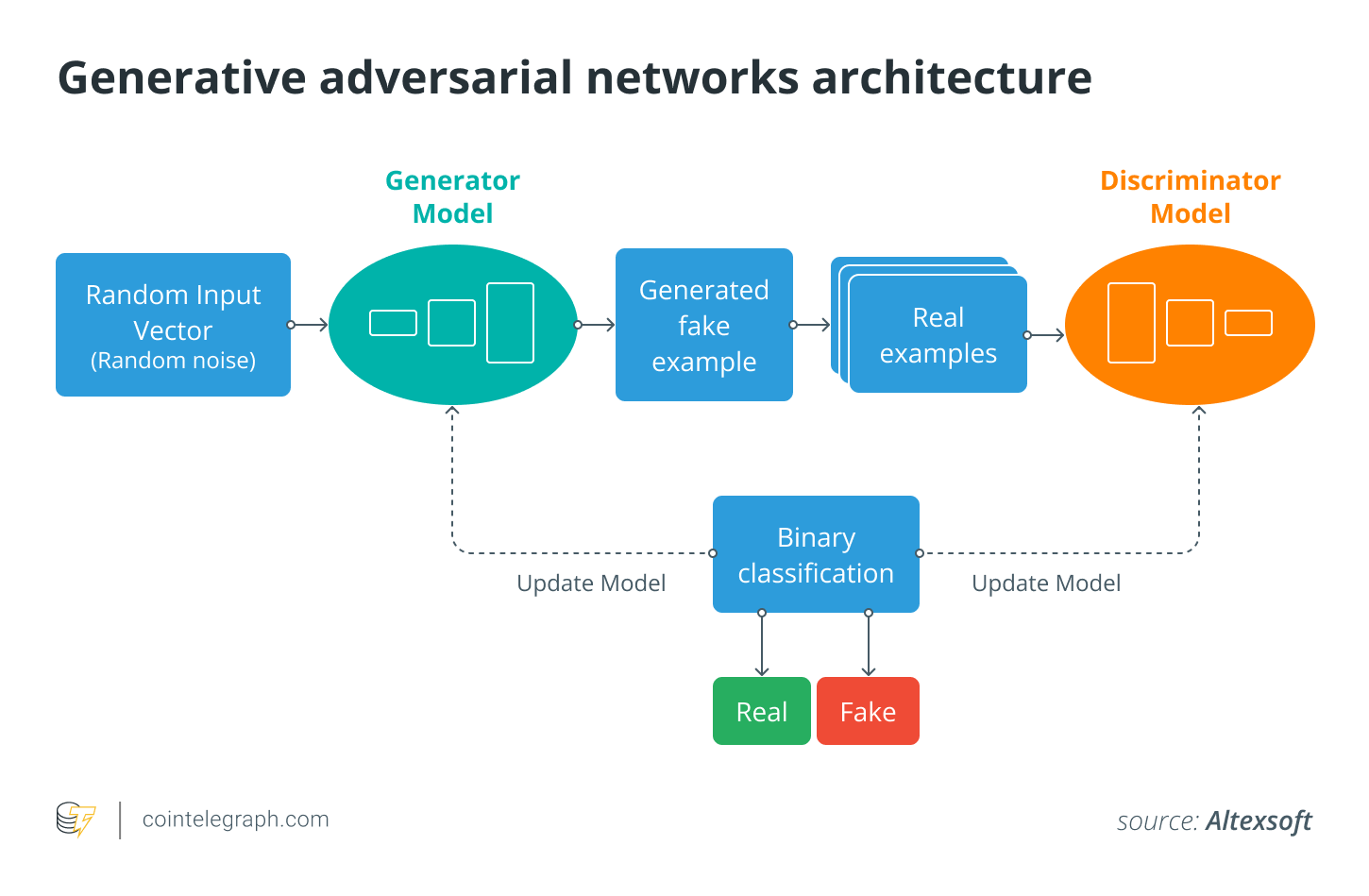
Обучение
Используя собранный набор данных, модель обучается. Изменяя свои внутренние параметры, модель изучает лежащие в основе шаблоны и свойства данных во время обучения. Итеративная оптимизация используется в процессе обучения, чтобы постепенно увеличивать способность модели создавать контент, который очень похож на обучающие данные.
Процесс генерации
После обучения модель может создавать новый контент путем выборки из наблюдаемого распределения обучающего набора. Например, при создании фотографий модель может использовать случайный вектор шума в качестве входных данных для создания изображения, похожего на реальное животное.
Оценка и доработка
Созданный материал исследуется для определения его калибровки и степени соответствия предполагаемым атрибутам. В зависимости от приложения для улучшения сгенерированного результата и разработки модели могут использоваться оценочные показатели и человеческий вклад. Повторяющиеся циклы обратной связи способствуют улучшению разнообразия и качества контента.
Точная настройка и передача обучения
Предварительно обученные модели иногда могут служить отправной точкой для обучения передаче и точной настройки определенных наборов данных или задач. Перенос обучения — это стратегия, которая позволяет моделям использовать информацию из одной области в другую и работать лучше при меньшем количестве обучающих данных.
Важно помнить, что точная работа моделей генеративного ИИ может меняться в зависимости от выбранной архитектуры и методов. Однако фундаментальная идея та же: модели обнаруживают закономерности в обучающих данных и создают новый контент на основе этих обнаруженных закономерностей.
Приложения генеративного ИИ
Генеративный ИИ изменил то, как мы создаем контент и взаимодействуем с ним, найдя множество применений в различных отраслях. Реалистичные визуальные эффекты и анимации теперь могут создаваться в изобразительном искусстве благодаря генеративному ИИ.
Способность художников создавать законченные пейзажи, персонажей и сценарии с поразительной глубиной и сложностью открыла новые возможности для цифрового искусства и дизайна. Универсальные алгоритмы ИИ могут создавать уникальные мелодии, гармонии и ритмы в контексте музыки, помогая музыкантам в их творческих процессах и обеспечивая свежее вдохновение.
Помимо творческих искусств, генеративный ИИ оказал значительное влияние на такие области, как игры и здравоохранение. Он использовался в здравоохранении для создания искусственных данных для медицинских исследований, позволяя исследователям обучать модели и исследовать новые методы лечения, не ставя под угрозу конфиденциальность пациентов. Геймеры могут испытать более захватывающий игровой процесс, создавая динамичные ландшафты и неигровых персонажей (NPC) с помощью генеративного ИИ.
Этические соображения
Разработка генеративного ИИ обладает огромным потенциалом, но она также поднимает важные этические вопросы. Одной из основных причин для беспокойства является глубоко поддельный контент, который использует контент, созданный искусственным интеллектом, для обмана людей и оказания на них влияния. Глубокие подделки способны подорвать доверие общественности к визуальным средствам массовой информации и распространять ложную информацию.
Кроме того, генеративный ИИ может непреднамеренно продолжать усиливать предвзятость, присутствующую в обучающих данных. Система ИИ может создавать материал, отражающий и усиливающий предубеждения, если данные, используемые для обучения моделей, являются предвзятыми. Это может иметь серьезные социальные последствия, такие как усиление стереотипов или маргинализация определенных сообществ.
Исследователи и разработчики должны уделять приоритетное внимание ответственной разработке ИИ для решения этих этических проблем. Это влечет за собой интеграцию систем для обеспечения открытости и объяснимости, тщательный отбор и диверсификацию наборов обучающих данных и создание четких правил для ответственного применения технологий генеративного ИИ.

Author: admin
Related Posts

Как центры обработки данных и энергетический сектор могут удовлетворить потребность искусственного интеллекта в энергии

Взгляд в будущее: как искусственный интеллект меняет нашу жизнь и к чему готовиться уже сегодня
