
Аннотация
В июле 2025 года в российском научно-технологическом пространстве был анонсирован амбициозный проект — аналитическая платформа Inventorus с интегрированным искусственным интеллектом «Никола». Проект позиционируется как суверенный ответ на санкционное ограничение доступа к глобальным наукометрическим базам данных и инструмент для обеспечения технологического лидерства. Настоящее исследование ставит целью провести объективный анализ платформы, сопоставив ее заявленные характеристики с эмпирическими данными, полученными в ходе первичного тестирования независимыми экспертами, и оценить ее реальный потенциал в контексте текущих вызовов.
1. Контекст и стратегическая необходимость
Формирование запроса на национальную научную платформу было обусловлено двумя ключевыми факторами. Во-первых, геополитическим — после 2022 года приостановка доступа к Web of Science и Scopus оставила российские научные организации без доступа к приблизительно 97,5% новых мировых публикаций. Во-вторых, технологическим — развитие больших языковых моделей (LLM) открыло возможность не просто агрегировать данные, а создавать интеллектуальные инструменты для их анализа.
В этом контексте Inventorus был представлен не просто как база данных, а как инфраструктурный элемент «технологического суверенитета». Проект получил поддержку на высшем государственном уровне, включая поручение президента РФ рассмотреть его включение в национальную подписку для научно-образовательных учреждений.
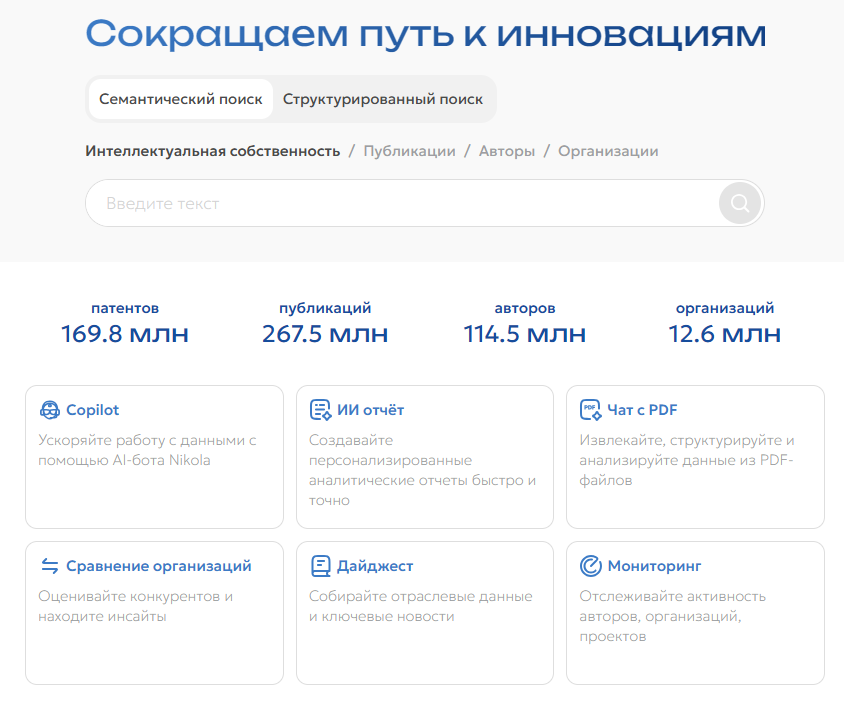
2. Декларируемые характеристики платформы
Согласно официальным заявлениям, платформа Inventorus обладает характеристиками, сопоставимыми с мировыми лидерами и даже превосходящими их в ряде аспектов:
- Корпус данных: Утверждается, что система индексирует свыше 500 миллионов документов, включая 256 млн научных статей и 154 млн патентов, обеспечивая 98% покрытие мирового научного знания.
- Интеллектуальные возможности AI «Никола»: Ключевым преимуществом названа способность модели работать без «галлюцинаций» благодаря обучению на верифицированном корпусе научных текстов. Заявлена поддержка 42 языков с корректным переводом терминологии и функция генерации аналитических рефератов.
- Инфраструктурная надежность: Платформа базируется в российском дата-центре уровня Tier III, что гарантирует высокую доступность сервиса.
3. Эмпирическая верификация: анализ первых результатов
Несмотря на масштабные декларации, первичное тестирование платформы независимыми пользователями из научной среды выявило существенный разрыв между заявленными возможностями и их текущей реализацией.
- Проблемы целостности и качества данных: Были зафиксированы как неполнота корпуса (отсутствие ряда актуальных публикаций в передовых областях, например, по CRISPR), так и системные ошибки в алгоритмах идентификации авторов (entity-matching), приводящие к созданию множественных дублирующихся профилей для одного ученого.
- Производительность и релевантность: Отмечена низкая релевантность поисковой выдачи, которая на целевые запросы часто возвращает патенты вместо ожидаемых статей. Время генерации аналитического отчета, достигающее 30 минут, не соответствует стандартам современных интерактивных систем, а его содержание не всегда коррелирует с запросом.
- Отсутствие методологической прозрачности: На момент исследования платформа не предоставляла публичной технической документации и API, что затрудняет ее интеграцию в существующие исследовательские процессы и независимую оценку качества ее работы.
4. Анализ и выводы
Inventorus представляет собой классический пример проекта, где стратегическое видение и политическая поддержка значительно опережают текущую технологическую готовность. На данный момент платформа находится на стадии минимально жизнеспособного продукта (MVP), функциональность которого не в полной мере соответствует заявленным характеристикам.
Особого внимания заслуживает тезис об отсутствии «галлюцинаций». В контексте современных LLM-архитектур, включая Retrieval-Augmented Generation (RAG), полное исключение логических ошибок или некорректного синтеза информации является пока недостижимой целью. Обучение на «чистых» данных снижает риск фактологических ошибок, но не гарантирует логической безупречности выводов. Таким образом, данное утверждение следует рассматривать скорее как маркетинговую цель, а не как подтвержденную техническую характеристику.
Заключение
Проект Inventorus обладает огромным стратегическим потенциалом и решает актуальную задачу обеспечения информационного суверенитета российской науки. Однако его будущее зависит от способности команды разработчиков в сжатые сроки преодолеть разрыв между амбициозным анонсом и реальным состоянием продукта. Для перехода от стадии «сырого» MVP к полноценному научному инструменту необходимо решение фундаментальных задач: обеспечение полноты и чистоты данных, радикальное повышение производительности и релевантности поиска, а также внедрение прозрачных метрик для верификации качества работы AI. Без этого проект рискует остаться витриной технологий, существующей в основном за счет административной поддержки, а не благодаря своей реальной пользе для научного сообщества.

Author: admin
Related Posts

Еженедельный дайджест КБ, ИИ и ИТ (16–22 января 2026)

Рекомендации CISA и партнёров по безопасной интеграции ИИ в операционные технологии критической инфраструктуры
