1. Введение
Растущее внедрение генеративного ИИ, особенно. Большие языковые модели (LLM), вновь вызвали дискуссию вокруг правил ИИ — для обеспечения ответственного обучения и развертывания систем ИИ / ОД. К сожалению, эта работа осложняется тем, что различные правительственные организации и регулирующие органы выпускают свои собственные руководства и политики практически без согласия относительно определения терминов. Язык спецификаций также (иногда намеренно) поддерживается на таком высоком уровне, что его трудно сопоставить с механизмом реализации / принудительного исполнения. Например, Закон ЕС об ИИ предписывает различный набор «можно и не нужно» в зависимости от «уровня риска’ приложения ИИ. Однако количественную оценку уровня риска приложения искусственного интеллекта легче сказать, чем сделать, поскольку это зависит от множества параметров,
и в основном требует от вас классифицировать, как возможности недетерминированной системы повлияют на пользователей и системы, которые могут взаимодействовать с ней в будущем.
Поэтому вместо того, чтобы пытаться понять и регулировать все типы систем ИИ, в этой статье мы используем другой (и практический) подход, т.е.,
прозрачно описать возможности системы искусственного интеллекта и установить реалистичные ожидания относительно того, что она может (или не может) делать.
Например, это означало бы, что поставщик системы искусственного интеллекта прозрачно заявляет, что модель была обучена на данных, содержащих определенные демографические данные, и что она может предоставлять прогнозы только для пользователей этих демографических данных — пользователи других демографических данных должны быть обработаны вручную. То есть поставщик системы искусственного интеллекта также определяет сценарии, в которых (по их мнению) система может допускать ошибки, и рекомендует ‘безопасный’ подход с ограждениями для этих сценариев.
Интуитивно мы можем рассматривать нормативный подход как проблему открытого мира, когда мы пытаемся регулировать все различные способы поведения системы (даже в будущем). В отличие от этого, прозрачность предложение занимает замкнутом мире подход, где он пытается коробка известные возможности системы — такие, что конечные пользователи и выходе системы может принять более обоснованное решение.
Подход ‘прозрачности’ также перекладывает бремя ответственности на предприятия / поставщиков, которым необходимо быть более прозрачными в отношении внутренних деталей своих систем ИИ.
Эти два подхода, конечно, могут дополнять друг друга, обеспечивая более надежную структуру, способствующую доверию пользователей к системе.
2. Ответственный ИИ
“Этичный ИИ, также известный как ответственный (или заслуживающий доверия) ИИ — это практика использования ИИ с благими намерениями расширить возможности сотрудников и бизнеса и справедливо повлиять на клиентов и общество. Этичный ИИ позволяет компаниям вызывать доверие и уверенно масштабировать ИИ ”. [1]
В дальнейшем мы кратко представим некоторые ключевые аспекты ответственного ИИ: объяснимость, предвзятость / справедливость, подотчетность — прежде чем изложить шаблоны проектирования решений для ИИ поколения. Четвертым аспектом будет ‘Конфиденциальность данных’, которая, по нашему мнению, уже получила достаточное освещение [2], и на предприятиях существуют зрелые практики для решения этих проблем.
2.1 Объяснимость
Объяснимый ИИ — это обобщающий термин для ряда инструментов, алгоритмов и методов; которые сопровождают прогнозы модели ИИ пояснениями. Объяснимость и прозрачность моделей ИИ явно занимают первое место в списке ‘нефункциональных’ функций ИИ, которые предприятия должны рассматривать в первую очередь. Например, это подразумевает необходимость объяснения того, почему модель ML определила принадлежность пользователя к определенному сегменту, что привело его к получению рекламы. Этот аспект также подпадает под ‘Право на объяснимость’ в большинстве нормативных актов, например, приведенный ниже абзац взят из Сингапурской системы управления ИИ:
“Следует отметить, что техническая объяснимость не всегда может быть поучительной, особенно для обывателя. Неявные объяснения того, как функционируют алгоритмы моделей ИИ, могут быть более полезными, чем явные описания логики моделей. Например, предоставление пользователю контрафактных фактов (таких как “вы были бы одобрены, если бы ваш средний долг был на 15% ниже” или “это пользователи с похожими на ваши профилями, которые получили другое решение”) может быть мощным объяснением, которое организации могли бы рассмотреть ”.
GDPR ЕС также распространяется на ‘Право на объяснимость’ — обратитесь к приведенным ниже статьям:
Ограничения в принятии решений, основанные исключительно на автоматизированной обработке и профилировании (статья 22)
Право на получение значимой информации о логике, задействованной в принятии решения (статьи 13, 15)
Обратите внимание, что GDPR не предусматривает ‘Права на объяснимость’, скорее, он предусматривает ‘Право на информацию’. GDPR действительно допускает возможность полностью автоматизированного принятия решений при условии, что не задействованы персональные данные, и целью не является оценка личности пользователя — в таких сценариях требуется вмешательство человека.
Специалисты по ИИ / ОД будут знать, что доступность данных и исходного кода — это не то же самое, что ‘объяснимость’. Алгоритмы машинного (глубокого) обучения различаются по уровню точности и объяснимости, которые они могут обеспечить — неудивительно, что часто эти два показателя обратно пропорциональны.
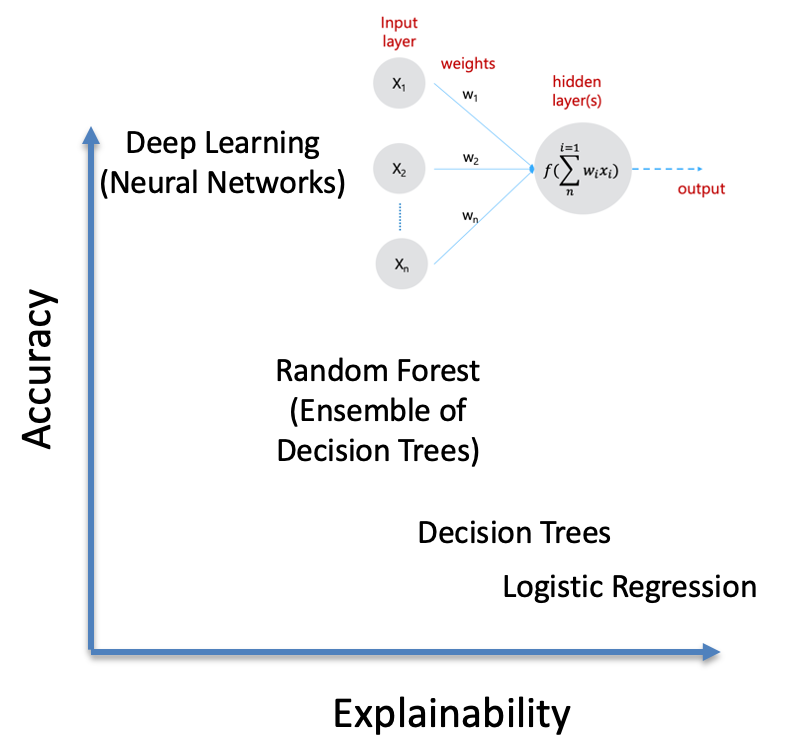
Например, фундаментальные алгоритмы ML, например, логистическая регрессия, деревья решений, обеспечивают лучшую объяснимость, поскольку можно отслеживать веса независимых переменных и коэффициенты, а также различные пути от узлов к листьям в дереве. Можно заметить, что «объяснимость» становится все более сложной по мере того, как мы переходим к случайным лесам, которые в основном представляют собой совокупность деревьев решений. В конце спектра находятся нейронные сети, которые показали точность на уровне человека. Очень сложно соотнести влияние (гипер) параметра, присвоенного слою нейронной сети, на окончательное решение — в глубокой (многослойной) нейронной сети. Это также причина, по которой оптимизация нейронной сети в настоящее время остается очень разовым и ручным процессом — часто основанным на интуиции специалиста по обработке данных [3].
Также важно понимать, что ‘объяснение’ может означать разные вещи для разных пользователей.
“важно правильно объяснить нужные вещи нужному человеку правильным способом в нужное время” [4]
Правильный уровень абстракции объяснения зависит от цели, знаний предметной области и способностей субъектов к пониманию сложности. Справедливо сказать, что большинство современных фреймворков объяснимости ориентированы на разработчика ИИ / ML.

Улучшение объяснимости моделей является активной областью исследований в сообществе ИИ / ОД, и достигнут значительный прогресс в системах объяснимости, не зависящих от модели. Как следует из названия, эти фреймворки отделяют объяснимость от модели, пытаясь соотнести предсказания модели с данными обучения, не требуя каких-либо знаний о внутренних элементах модели.
Например, одной из наиболее известных фреймворков объяснимости, не зависящих от модели, являются локальные интерпретируемые объяснения, не зависящие от модели (LIME). LIME — это “новая методика объяснения, которая объясняет предсказания любого классификатора интерпретируемым и достоверным образом путем локального изучения интерпретируемой модели вокруг прогноза”. LIME предоставляет простые для понимания (приблизительные) объяснения прогноза путем обучения модели объяснимости на основе выборок вокруг прогноза. Затем он взвешивает их на основе их близости к исходному прогнозу. Приблизительный характер модели объяснимости может ограничить ее использование для обеспечения соответствия требованиям.
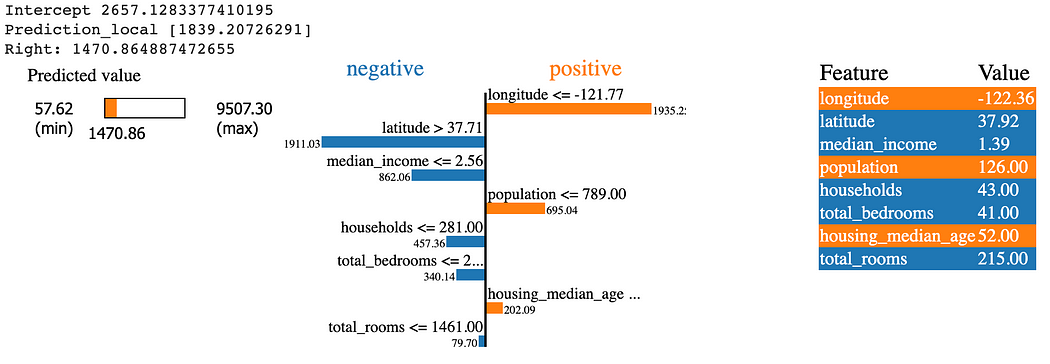
Например, на приведенном ниже снимке показан результат LIME искусственной нейронной сети (ANN), обученной на подмножестве набора данных о ценах на жилье в Калифорнии. В нем показаны важные особенности, положительно и отрицательно влияющие на прогноз модели.
Как упоминалось, это активная область исследований, и прогресс продолжается с выпуском большего количества таких (иногда специфичных для модели) фреймворков и инструментов объяснения.
2.2 Предвзятость и справедливость
[5] определяет предвзятость ИИ / ML “как явление, возникающее, когда алгоритм выдает результаты, которые системно искажены из-за ошибочных предположений в процессе машинного обучения”.
Смещение в моделях AI / ML часто непреднамеренно, однако оно слишком часто наблюдается в развернутых вариантах использования, чтобы к нему можно было относиться легкомысленно. Google Photo помечает фотографии чернокожего гаитянско-американского программиста как “гориллу” к более свежим изображениям “Белого Барака Обамы”; это примеры моделей ML, дискриминирующих по полу, возрасту, сексуальной ориентации и т.д. Непреднамеренный характер таких предубеждений не помешает вашему предприятию быть оштрафованным регулирующими органами или столкнуться с негативной реакцией общественности в социальных сетях, что приведет к потере бизнеса. Даже без вышеуказанных последствий просто этично, что модели AI / ML должны вести себя честно по отношению ко всем, без какой-либо предвзятости. Однако определение ‘справедливости’ легче сказать, чем сделать. Означает ли справедливость, например, что одинаковая доля кандидатов мужского и женского пола получает высокие баллы по оценке риска? Или что одинаковый уровень риска приводит к одинаковым баллам независимо от пола? Невозможно выполнить оба определения одновременно [6].
Предвзятость проникает в модели ИИ, в первую очередь из-за присущей им предвзятости, уже присутствующей в обучающих данных. Таким образом, ‘информационная’ часть разработки модели ИИ является ключом к устранению предвзятости.
В [7] приведена хорошая классификация различных типов ‘предвзятости’, возникающих на разных этапах жизненного цикла разработки ИИ / ML:
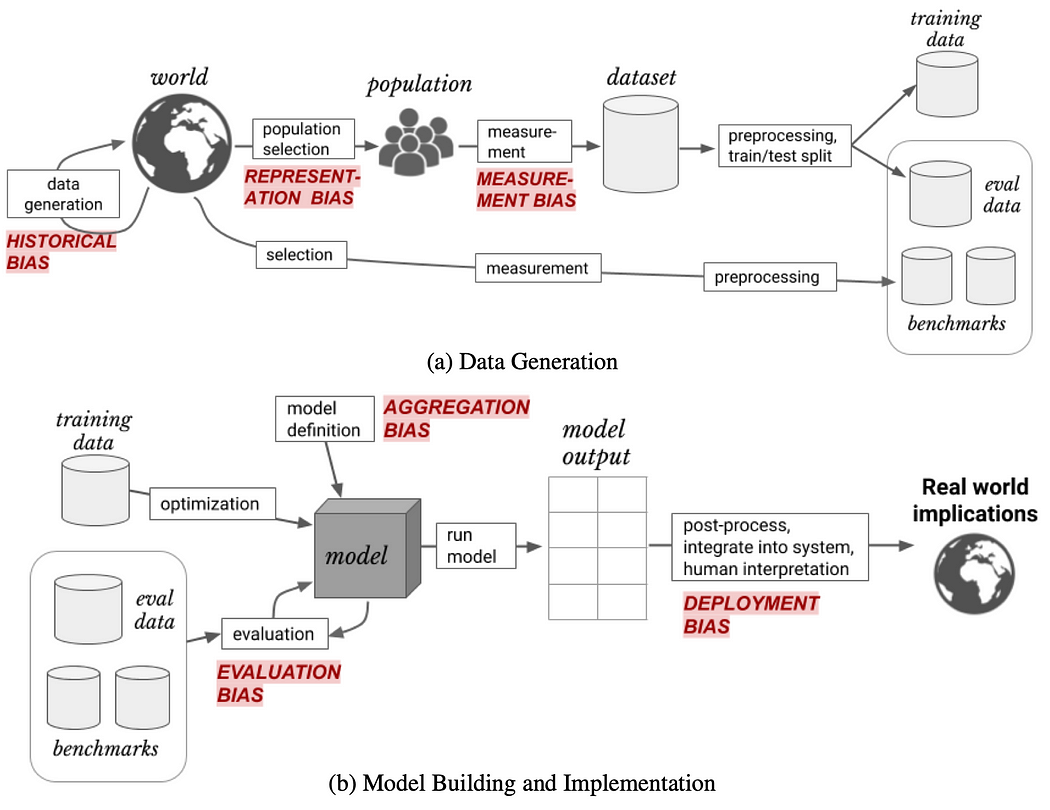
Сосредоточение внимания на типах смещений, связанных с «обучающими данными»,
- Историческая предвзятость: возникает из-за исторического неравенства человеческих решений, отраженных в данных обучения
- Смещение представления: возникает из-за данных обучения, которые не являются репрезентативными для реальной совокупности
- Погрешность измерения и агрегирования: возникает из-за неправильного выбора и сочетания функций.
Необходим подробный анализ обучающих данных, чтобы гарантировать, что они репрезентативны и равномерно распределены по целевой совокупности в отношении выбранных функций. Объяснимость также играет важную роль в обнаружении смещений в моделях AI / ML.
Что касается инструментов, индикаторы справедливости TensorFlow (ссылка) — хороший пример библиотеки, которая позволяет легко вычислять общепринятые показатели справедливости.
Здесь важно упомянуть, что обнаружение смещения — это не разовое действие. Подобно мониторингу дрейфа модели, нам нужно планировать, чтобы обнаружение смещения выполнялось на постоянной основе (в режиме реального времени). По мере поступления новых данных (включая циклы обратной связи) модель, которая беспристрастна сегодня, может стать предвзятой завтра. Например, это то, что произошло с чат-ботом с искусственным интеллектом «девочка-подросток» от Microsoft, который в течение нескольких часов после его развертывания научился превращаться в “секс-робота, любящего Гитлера”.
2.3 Подотчетность
Аналогично дебатам о самоуправляемых автомобилях в отношении того, “кто несет ответственность”, если произойдет авария? Это пользователь, производитель автомобиля, страховая компания или даже городской муниципалитет (из-за проблемы с дорогой / светофорными сигналами)? Те же дебаты применимы и в случае моделей ИИ — кто несет ответственность, если что-то пойдет не так?, например, как объяснялось выше в случае предвзятого развертывания модели ИИ.
Ниже мы изложим несколько вопросов (в форме контрольного списка), которые вам необходимо рассмотреть / уточнить перед подписанием контракта с предпочитаемым вами поставщиком генераторного ИИ:
- Ответственность: Учитывая, что мы сотрудничаем со третьей стороной, в какой степени они несут ответственность? Об этом сложно договориться и зависит от степени, в которой система ИИ может работать независимо. Например, в случае чат-бота, если боту разрешено предоставлять только ограниченный результат (например, отвечать пользователю ограниченным количеством предварительно утвержденных ответов), то риск, вероятно, будет намного ниже по сравнению с открытым ботом, таким как ChatGPT, который может генерировать новые ответы.
- Владение данными: данные имеют решающее значение для систем ИИ, поскольку такое согласование вопросов владения не только обучающими данными, но и входными, выходными и другими сгенерированными данными имеет решающее значение. Например, знание подсказок (пользовательских запросов) и ответов чат-бота очень важно для повышения производительности бота с течением времени.
- Положения о конфиденциальности : В дополнение к конфиденциальности данных (обучения), хотим ли мы помешать поставщику предоставлять конкурентам доступ к обученной / отлаженной модели или, по крайней мере, к каким—либо ее улучшениям, особенно если это дает конкурентное преимущество?
3. Разработка решения
На данный момент мы выделили ключевые аспекты разработки и внедрения моделей ИИ / ОД, которые нам необходимо начать рассматривать сегодня — как часть целостной ответственной структуры ИИ для предприятий.
Как и во всем в жизни, особенно. в ИИ нет четкого черно-белого, а общая политика ИИ, предписывающая использовать только объяснимые модели AI / ML, не является оптимальной — подразумевает упускание того, что могут предоставить необъяснимые алгоритмы.
В зависимости от варианта использования и географических правил всегда есть возможности для переговоров. Правила, относящиеся к различным вариантам использования (например, профилирование, автоматизированное принятие решений), различаются в разных географических регионах. Что касается предвзятости и объяснимости, у нас также есть полный спектр от ‘полностью объяснимого’ до ‘частично объяснимого, но проверяемого’ до ‘полностью непрозрачного, но с очень высокой точностью’. Учитывая это, необходимо сформировать знающую и междисциплинарную команду (состоящую, по крайней мере, из ИТ-специалистов, юристов, представителей отдела закупок, бизнеса), часто называемую Комитетом по этике ИИ, — которая может последовательно принимать такие решения в соответствии с ценностями и стратегией компании.
3.1 Принципы проектирования решений
В этом разделе мы обсуждаем принципы проектирования, позволяющие использовать ‘прозрачный’ подход к определению возможностей (и ограничений) приложения Gen AI — устанавливать реалистичные ожидания пользователей.
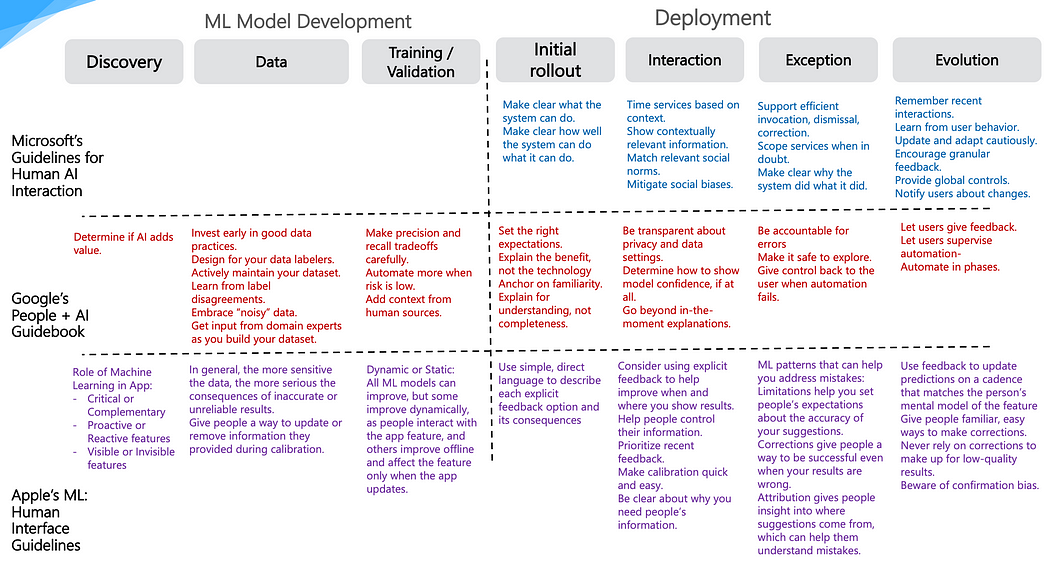
Вместо того, чтобы пытаться изобрести новую структуру, мы черпаем вдохновение из “дружественных к предприятию” Microsoft, “дружественных к разработчикам” Google и “удобных для пользователей” Apple — чтобы обеспечить этот «прозрачный» подход к проектированию систем Gen AI. Давайте взглянем на фреймворки проектирования ИИ, рекомендованные этими тремя лидерами:
- Рекомендации по взаимодействию человека и ИИ от Microsoft
- Руководство по людям + ИИ от Google
- Машинное обучение: рекомендации по человеческому интерфейсу от Apple
На рисунке ниже объединены принципы и лучшие практики из 3 спецификаций на разных этапах конвейера LLMOps (MLOps для LLMs) [8].
Список литературы
- Р. Э. Портер. За гранью обещания: внедрение этичного ИИ (ссылка)
- Д. Бисвас. Сохранение конфиденциальности разговоров чат-ботов. В рамках 3-го семинара NeurIPS по машинному обучению с сохранением конфиденциальности (PPML), 2020 (документ)
- Д. Бисвас. Готов ли AutoML к бизнесу?. На пути к науке о данных, 2020 (ссылка)
- Н. Се и др. Объяснимое глубокое обучение: практическое руководство для непосвященных (ссылка)
- Искусственный интеллект для поискового предприятия. Предвзятость машинного обучения (AI bias) (ссылка)
- К. Хао. Вот как на самом деле происходит смещение ИИ — и почему это так трудно исправить ,,,,(ссылка)
- Х. Суреш, Дж. В. Гуттаг. Основа для понимания непреднамеренных последствий машинного обучения (ссылка)
- Д. Бисвас. Шаблоны архитектуры генеративного ИИ — LLMOps. Инвестор, ориентированный на данные (ссылка)
- Дж.Д. Вайс. К общим принципам проектирования приложений с генеративным ИИ, 2023 (ссылка)

Author: admin
Related Posts

Еженедельный дайджест КБ, ИИ и ИТ (16–22 января 2026)

Рекомендации CISA и партнёров по безопасной интеграции ИИ в операционные технологии критической инфраструктуры
