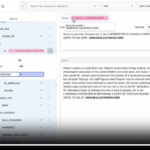
Lilac — это инструмент с открытым исходным кодом, который позволяет специалистам по ИИ просматривать и количественно оценивать свои наборы данных.
Полный пример смотрите в нашем кратком начале работы.
Для получения подробной документации посетите наш веб-сайт.
Lilac позволяет пользователям:
- Просматривайте наборы данных с неструктурированными данными.
- Обогащайте неструктурированные поля структурированными метаданными, используя сиреневые сигналы, например, почти повторяющиеся и обнаружение личной информации. Структурированные метаданные позволяют нам вычислять статистику, находить проблемные фрагменты и в конечном итоге измерять изменения с течением времени.
- Создавайте и совершенствуйте концепции Lilac, которые представляют собой настраиваемые модели искусственного интеллекта, которые можно использовать для поиска и оценки текста, соответствующего концепции, которая может возникнуть у вас в голове.
- Загрузите результаты обогащения для последующих приложений.
Из коробки Lilac поставляется с набором общеполезных сигналов и концепций, однако этот список не является исчерпывающим, и мы продолжим работать с сообществом OSS, чтобы продолжать добавлять более полезные дополнения.
Наша миссия
Наша миссия в Lilac — сделать неструктурированные данные видимыми, поддающимися количественной оценке и гибкими.
Это приведет к:
- Модели искусственного интеллекта более высокого качества
- Повышение эффективности действий при сбое моделей искусственного интеллекта
- Лучший контроль и наглядность смещения модели
Качество данных в ИИ — сложная штука
За время работы в Google мы сотрудничали со многими командами над улучшением наборов данных, используемых для построения их моделей искусственного интеллекта. Их целью было постоянное улучшение качества своих моделей, часто фокусируясь на уточнении обучающих данных.
Что затрудняет улучшение качества данных, так это то, что многие модели искусственного интеллекта полагаются на неструктурированные данные, такие как естественный язык или изображения, в которых отсутствуют какие-либо метки или полезные метаданные. Чтобы усложнить ситуацию, то, что считается “хорошими” данными, в значительной степени зависит от приложения и пользовательского опыта. Несмотря на эти различия, появилась общая нить: в то время как команды вычисляли совокупную статистику, чтобы понять общую структуру своих данных, они часто упускали из виду исходные данные. При методичной организации и визуализации вопиющие ошибки в наборах данных проявились бы сами собой, часто с простыми исправлениями, приводящими к созданию моделей более высокого качества.
“Неверные данные”
“Неверные данные” часто трудно определить, но мы часто распознаем неверные данные, когда видим их. В других случаях “плохие данные” не являются объективно плохими: например, наличие немецкого текста в наборе данных о переводе с французского на английский негативно повлияет на модель перевода, даже если перевод правильный для немецкого.
Помня об этом наблюдении, в Google мы создали инструменты и процессы, которые позволили командам просматривать свои данные. Подведем итог нескольким годам обучения в одном предложении: у каждого набора данных есть свои особенности, и эти особенности могут иметь неочевидные последствия для качества последующих моделей.
Сегодня очистка данных для наборов данных, загружаемых в модели искусственного интеллекта, часто выполняется с помощью эвристики в скрипте Python, при этом побочные эффекты этого изменения практически не видны.
Концепции
Поскольку у каждого приложения искусственного интеллекта свои требования, мы сосредоточены на том, чтобы дать пользователям возможность комментировать данные с помощью настраиваемых концепций. Концепции могут быть созданы и доработаны с помощью пользовательского интерфейса и обновлены в режиме реального времени с помощью отзывов пользователей. Эти классификаторы на основе встраивания на базе искусственного интеллекта могут быть специфичными для конкретного приложения, например, положения о расторжении юридических контрактов, или общеприменимыми, например, токсичность.
На устройстве
Конфиденциальность данных является важным фактором для большинства команд искусственного интеллекта, поэтому мы сосредоточены на том, чтобы сделать Lilac быстрым и удобным, при этом данные остаются локальными. Концепции Lilac используют мощные встраивания в устройства, такие как GTE. Однако, если ваше приложение не чувствительно к конфиденциальности данных (например, при использовании наборов данных с открытым исходным кодом), вы можете использовать более мощные встраивания, такие как OpenAI, Cohere, PaLM или ваши собственные! Для получения дополнительной информации о встраиваниях, смотрите нашу документацию.
Демо-версия HuggingFace
Мы также размещаем пространство HuggingFace с несколькими популярными наборами данных (например, OpenOrca) и кураторскими концепциями (например, ненормативная лексика, юридическое прекращение деятельности, обнаружение исходного кода и т.д.). В этой демонстрации вы можете просматривать предварительно обогащенные наборы данных и даже создавать свои собственные концепции. Пространство можно разделить и сделать приватным с вашими собственными данными, пропустив процесс установки Lilac.
С открытым исходным кодом
Мы считаем, что продукт с открытым исходным кодом — лучший способ улучшить культуру в отношении качества набора данных.
Мы призываем сообщество искусственного интеллекта опробовать этот инструмент и помочь нам создать центральное хранилище полезных концепций и сигналов. Мы хотели бы сотрудничать, чтобы пролить свет на самые популярные наборы данных искусственного интеллекта.
Давайте визуализируем, подсчитаем и, в конечном счете, улучшим все неструктурированные наборы данных.

Author: admin
Related Posts

Еженедельный дайджест КБ, ИИ и ИТ (16–22 января 2026)

Рекомендации CISA и партнёров по безопасной интеграции ИИ в операционные технологии критической инфраструктуры
